Loading…
Private AI on your own hardware.
iPhone to Mac cluster to private LLM. No cloud APIs. Your data never leaves your network. Deploy AI agents across Apple Silicon nodes connected via Thunderbolt 5 RDMA.
Powered by
Apple Silicon
MLX
Tailscale
TB5 RDMA
Apple Silicon
MLX
Tailscale
TB5 RDMA
Apple Silicon
MLX
Tailscale
TB5 RDMA
Apple Silicon
MLX
Tailscale
TB5 RDMA
r1o — Cluster Topology
1.5 TB Unified
/// WHY THIS EXISTS
Cloud AI has a trust problem
Every major AI provider reads your data, charges you per word, and can change the rules at any time. r1o fixes all of it.
They read your prompts
Every message stays on your Mac
Cloud AI providers log, store, and train on your conversations. With r1o, your prompts never leave your network. Not even we can see them.
They charge per token
Unlimited, forever, for free
No API keys. No monthly bills. No throttling at 3am when you need it most. Your hardware, your electricity — that's it.
They control the model
Run any model you want
Choose from hundreds of open-source models. No vendor decides which capabilities you get. Switch models in seconds, not procurement cycles.
They can shut it off
Yours works offline
API goes down? Rate limited? Terms changed? Doesn't matter. r1o runs on your desk. Unplug the ethernet and it still works.
They own your data
You own everything
Your conversations, your models, your fine-tunes, your embeddings. All on hardware you physically possess. No EULA can take it away.
They see your business
Total confidentiality
Legal docs. Medical records. Source code. Trade secrets. Use AI on your most sensitive work without worrying who's watching.
/// FROM ZERO TO SOVEREIGN AI
Four steps. Under 30 minutes.
No expertise required. Each step has a script that does the work for you.
01
Run one script
Download and run r1o-fresh-start.sh. It installs everything your Mac needs — Homebrew, Python, AI frameworks. Takes 5 minutes.
r1o-fresh-start.sh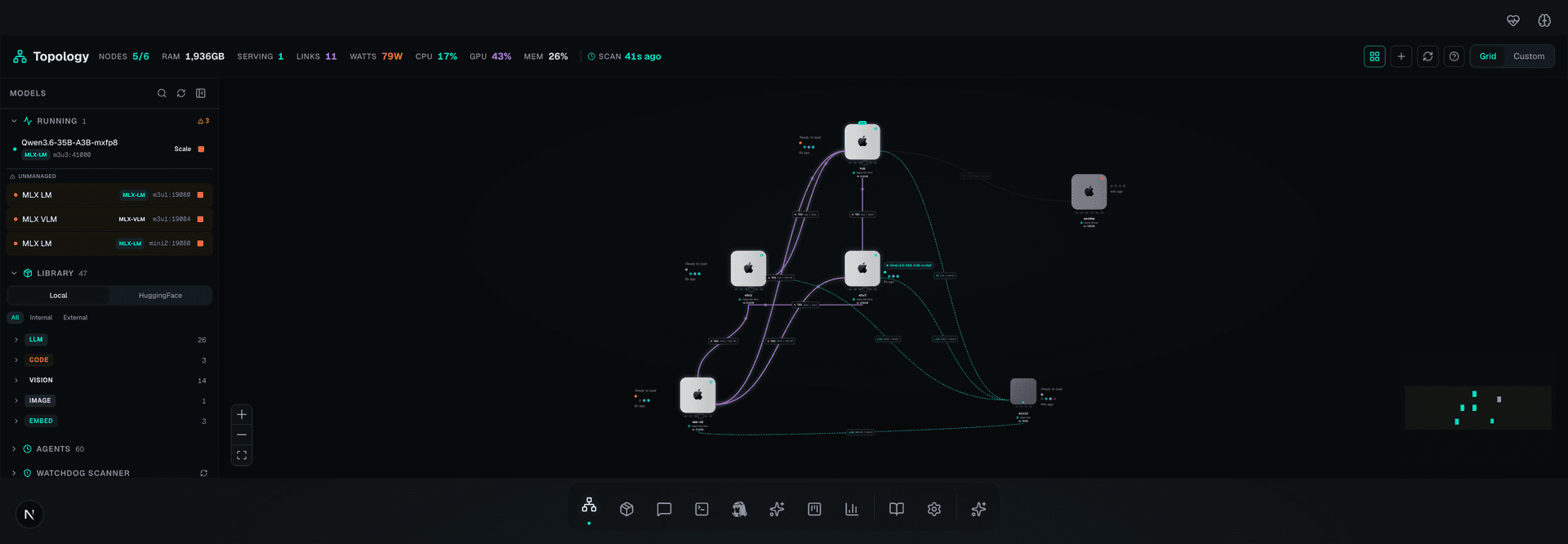
02
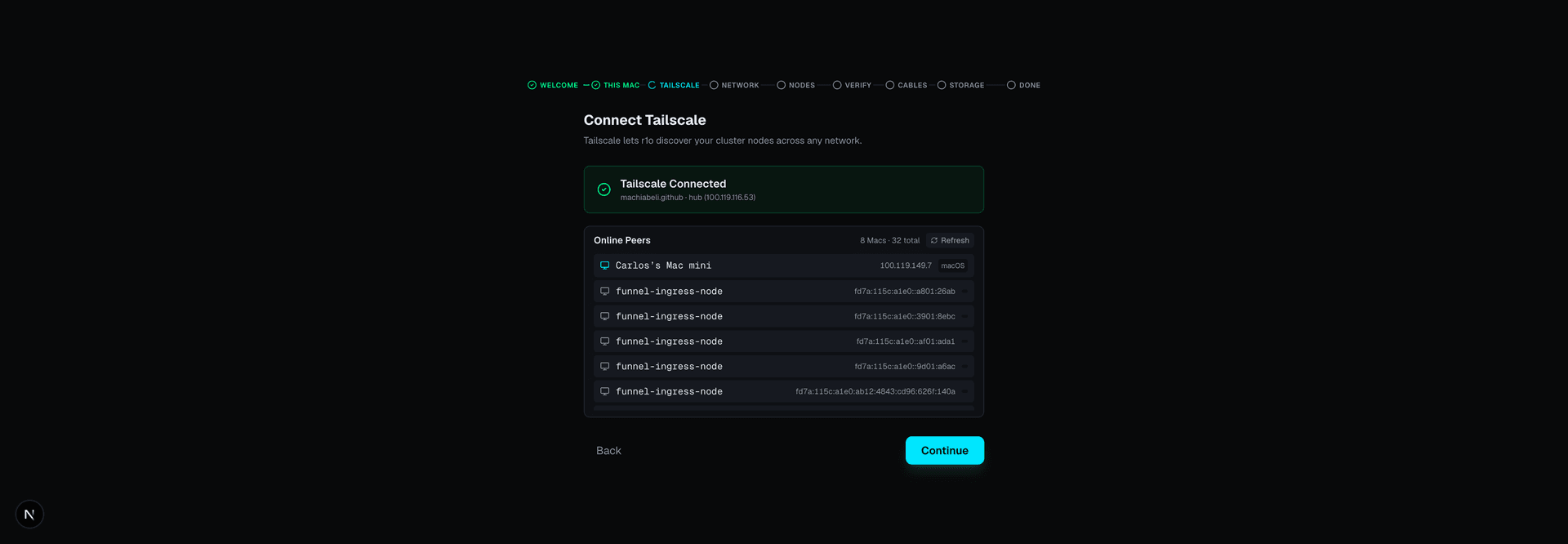
Connect your Macs
Plug in a Thunderbolt cable between your Macs. r1o discovers them automatically and maps the high-speed connections.
r1o-enable-rdma.sh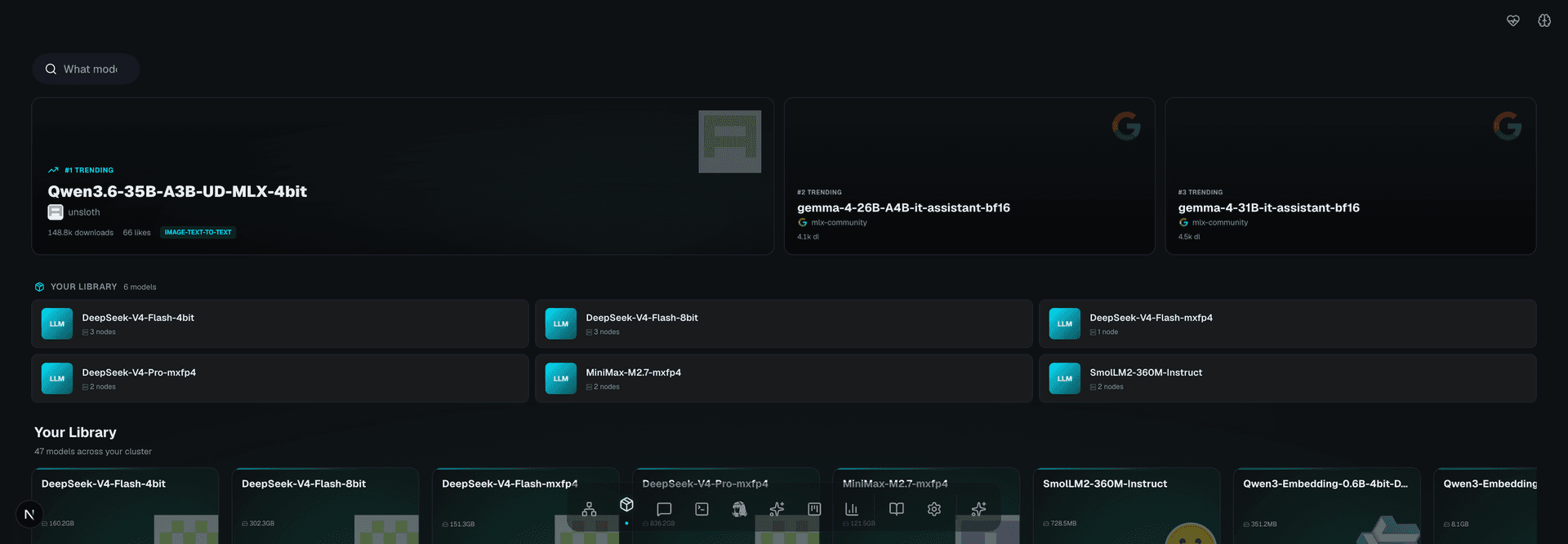
03
Pick a model
Browse hundreds of open-source AI models. Pick one, click download. It's on your Mac in minutes — no account needed.
r1o-deploy-model.sh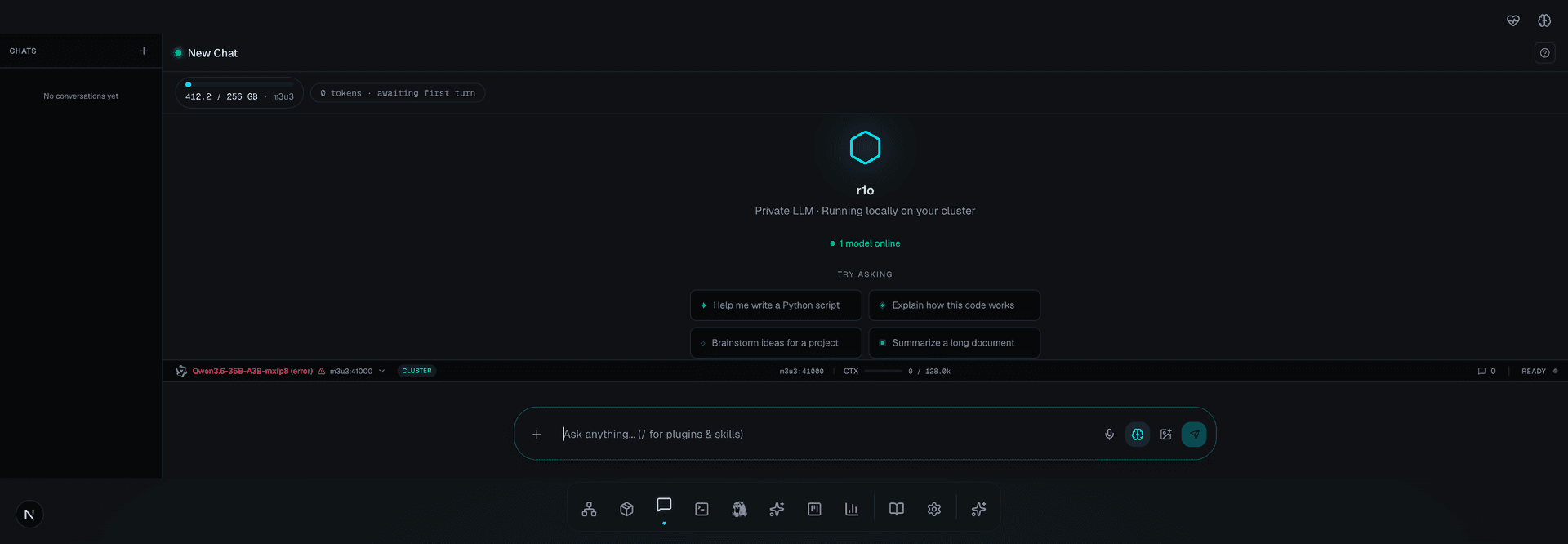
04
Start talking
Open the chat and ask anything. Your AI runs on your desk. Every conversation is private. No one else can see it.
/// THE WALKTHROUGH
Boxed Mac to private inference in 29 minutes
Five missions. Each step is reversible until you reach the wizard. Real screenshots, real terminal output, and a chat assistant that only answers from the docs themselves.
Your pocket LLM awaits
Set up your Mac cluster, point your iPhone, and start chatting with private AI. Five minutes to first inference.